

AI adoption is accelerating across nearly every major industry, yet the return on these investments remains inconsistent and often disappointing. While underperformance is frequently attributed to model drift or technical shortcomings, the underlying issue is far more structural. Organizations continue to build intelligent systems on top of fragmented, incomplete, and inaccessible data.
In many cases, the real problem is not the machine learning models themselves but the data infrastructure feeding them. Until leaders prioritize unifying their data ecosystems, AI initiatives will struggle to produce measurable value, no matter how advanced the models become.
Misdiagnosing The Problem Leads To Repeated Failure
When the performance of an AI model begins to decline, it is natural for teams to look inward at the model itself. They often assume that something in the algorithm has changed or that the model has simply “drifted” from its original training distribution. From there, the focus tends to shift toward tuning hyperparameters, reweighting datasets, or re-engineering the model entirely.
What rarely gets examined first is the changing nature of the data itself.
In many cases, the problem originates from updates in upstream systems, undocumented shifts in how teams use business platforms, or inconsistencies introduced through manual processes. The model may still be technically sound, but if the data inputs have degraded or lost alignment with real-time business operations, performance will inevitably follow.
The Structural Barriers Hiding In Plain Sight
In enterprise environments, data fragmentation is not a coincidence but a result of long-standing operational patterns, competing priorities between departments, and legacy systems that were never designed to work together. These silos are rarely visible in organizational charts, but they are deeply embedded in the architecture of the business.
Sales, marketing, finance, and operations often maintain their own separate systems, each with unique data schemas, governance policies, and access controls. Even when there is an initiative to centralize information, the integration is frequently superficial, with limited contextual understanding between systems.
These realities lead to serious complications during AI deployment. Models rely on consistent and context-rich inputs to generate meaningful outputs. When a customer record is defined one way in the CRM and another in the billing system, the model is essentially trying to learn from conflicting versions of the truth. Add in batch ETL pipelines that refresh only once a day, data updates managed through manual spreadsheets, and external datasets lacking standardized formatting, and the outcome is predictable.
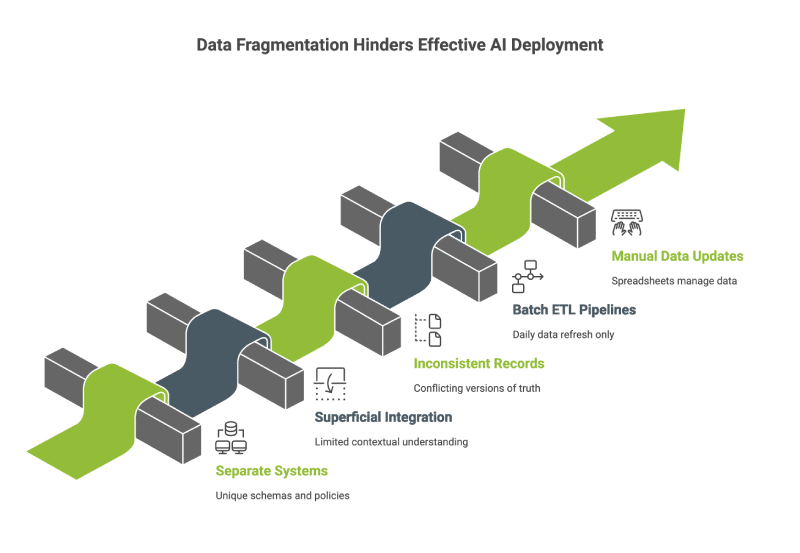
Rather than producing clarity, the AI system simply reflects the disjointed nature of the organization’s data, leading to unpredictable behavior and eroding stakeholder trust. Many organization’s are able to rectify these knowledge fragmentation issues by implementing AI & data management solutions.
Models Cannot Compensate For Incomplete Foundations
As model performance plateaus or declines, organizations often respond by upgrading to more complex architectures. Deep learning, ensemble modeling, or transformer-based solutions are introduced in hopes of gaining back predictive power. Yet these upgrades rarely produce the intended ROI, because the underlying data inputs are still riddled with inconsistencies.
Advanced algorithms may improve marginally under ideal conditions, but they cannot compensate for missing data, misaligned categories, or degraded signal quality. Without the ability to consistently observe data quality and structure in real time, the most sophisticated model becomes little more than an educated guess.
In many environments, there is no early warning system when a critical input starts degrading or when new fields are introduced without proper documentation. This absence of visibility makes the entire pipeline brittle. What organizations often interpret as model drift is frequently just a symptom of infrastructure that is not designed to support evolving operations.
Until the data supply chain is stabilized and continuously monitored, model upgrades will continue to deliver diminishing returns.
Learn How To Start Restructuring Your Organization For AI
What A Sustainable AI Modernization Stack Actually Looks Like
To modernize AI in a way that leads to consistent, measurable value, organizations must begin by modernizing the systems around it. This means creating a data foundation that supports real-time, unified, and trustworthy inputs across every stage of the AI lifecycle. The first step is ensuring cross-functional access to data through a shared architecture. Core business systems such as CRMs, ERPs, and analytics platforms should be integrated through APIs or unified data layers that eliminate duplication and synchronize updates in real time.
Equally important is the adoption of shared definitions. Terms like “customer,” “lead,” or “transaction” must mean the same thing across all departments. Without a common language, the risk of misinterpretation multiplies, especially when these terms are embedded in model training. The data pipeline must also move beyond static ETL jobs toward real-time ingestion with validation layers that ensure consistency and integrity. Data observability tools should be implemented to track schema changes, monitor for missing fields, and alert teams to anomalies before they cascade into model degradation.
Finally, governance is critical. Every dataset used in training or inference should have a known owner, documented lineage, and clear policies for updating, retiring, or modifying its contents.
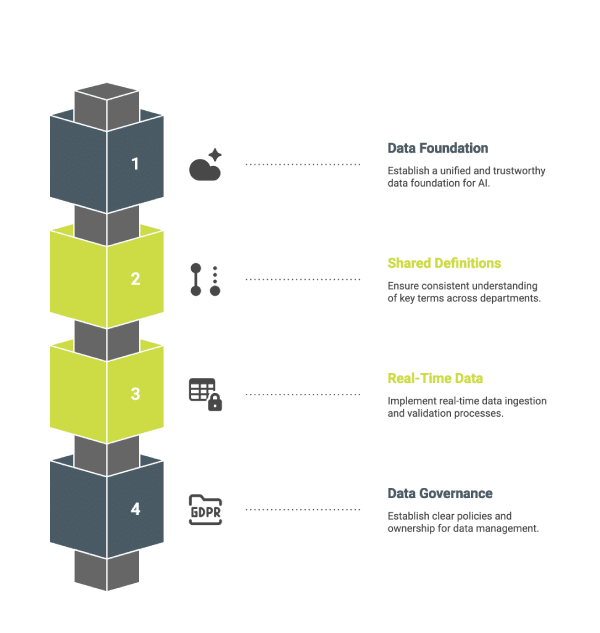
These foundational controls make it possible to scale AI systems with confidence and minimize the risk of unpredictable outcomes.
Breaking Silos Requires More Than Technology
Responsibility for data cannot be distributed in a way that encourages teams to optimize in isolation. Instead, shared accountability must be built into project governance. Data teams, business analysts, and operational leaders should be working from the same playbook, with unified objectives and a common understanding of how data will be used downstream.
Organizations that see data engineering as a support function to data science are also likely to encounter persistent friction. In reality, the two functions must work in lockstep, beginning at the planning phase of any AI initiative. When infrastructure is treated as an afterthought, technical debt is baked into the project from the beginning.
Appointing a Chief Data Officer or a similar role to own enterprise-wide data architecture is often a necessary first step. Without clear leadership, the organization will continue to optimize models on top of a broken foundation.
Fix The Inputs Before You Blame The Output
Orases partners with executive teams to help identify the structural causes behind underperforming AI initiatives. We specialize in designing data infrastructure that enables reliable, real-time intelligence across your organization.
If you’re ready to move beyond experimentation and start building an AI foundation that delivers tangible results, schedule a consultation with our team.
